Ingesting X12 EDI Implementation Guides with an Agentic Pipeline

Adrian Duyzer
Introduction
I spent several months building, testing and refining an agentic pipeline capable of reliably importing a trading partner implementation guide into Tediware. In other words, I built an automated process that turns this:

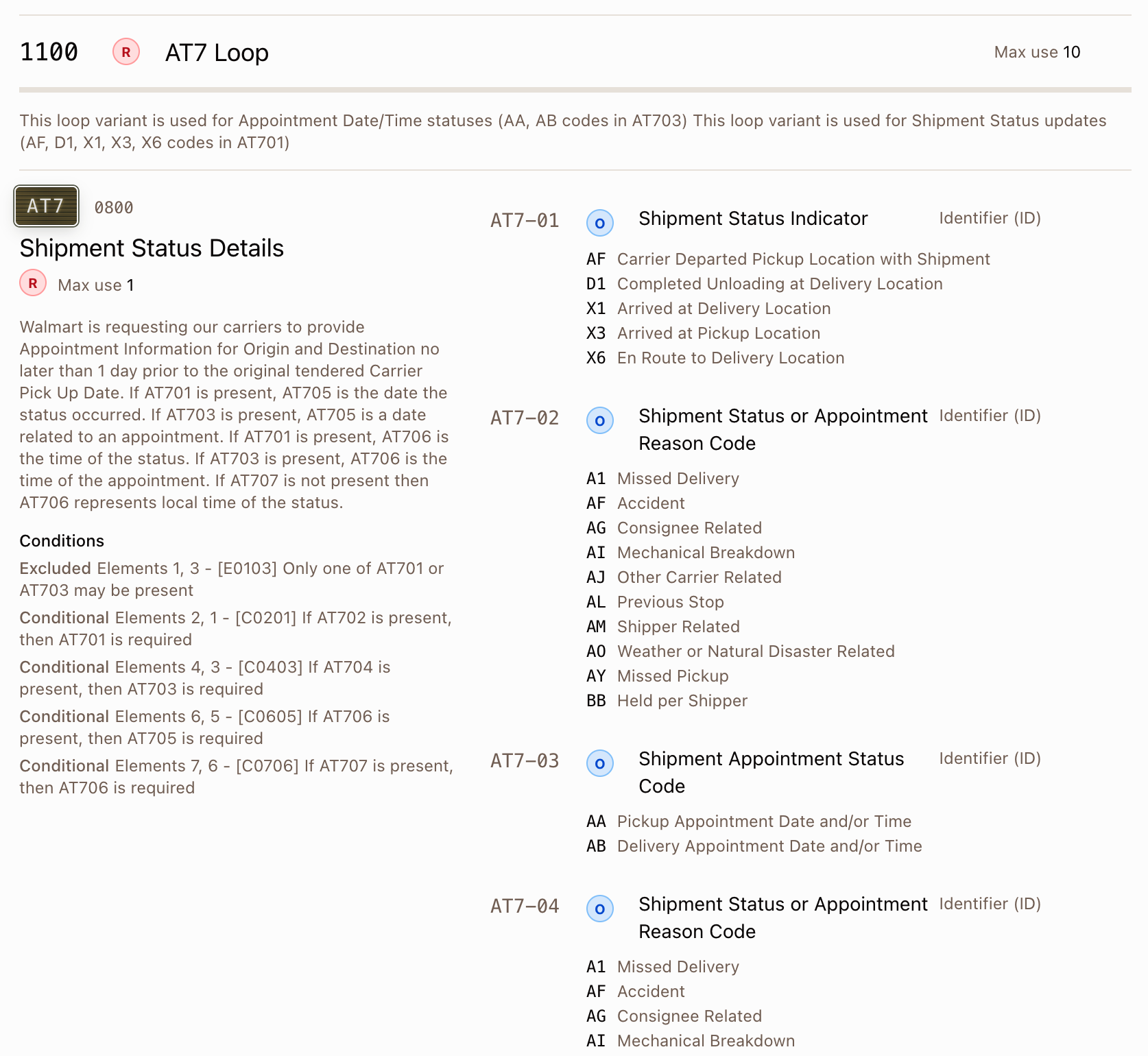
Into machine-readable guides that can be viewed, edited and used in automated processes including EDI validation, AI-assisted mapping, and EDI generation:
This article will teach you (or your technical team) how to build an agentic pipeline of your own. This introduction is geared towards a general audience: I’ll explain why I built this process and why it was worth it. Starting in section 1, the discussion becomes more technical: it is written for an audience with a strong understanding of X12 EDI, systems design, and state-of-the-art agentic processes.
The technical sections describe the shape of a working ingestion system and the design decisions that matter. I focus mainly on what works, but I also outline some of the failure modes that cost the most time. It is not, however, a copy-and-paste recipe (it doesn’t include the prompts, for example). The goal is to distill months of iteration into a map that you can follow and improve on.
If you’d rather get into the technical details, skip to Section 1: What Is “Spec Ingestion”, Exactly? Otherwise, read on for why machine-readable guides are worth creating and why their creation is worth automating.
Why machine-readable implementation guides?
Traditionally, an EDI analyst or integration specialist at a company reads a guide from a trading partner and uses it as the basis for an arduous, time-consuming process of data transformation (usually called “mapping”), where inbound and outbound data is manipulated so it is suitable for the company’s purposes (inbound) or the purposes of their trading partner (outbound).
Outbound data that the company wants to send to its partner must comply with that partner’s specifications as outlined in the guide. The analyst creates a mapping in their system, generates an outbound document, and examines the EDI to judge its compliance with the guide. When they are satisfied it complies, they typically send a test transmission to their trading partner, who can then test whether it is processed cleanly by their system. This back-and-forth process often takes weeks.
A machine-readable guide fundamentally changes that process. Once an implementation guide exists in Tediware, it is used to:
- Generate a schema which is used to validate outbound data. If the outbound data is valid according to the schema, it is highly likely it will import cleanly, on the first try, when it is sent to the partner.
- Automate the mapping process. We can use AI to generate mappings without human involvement. Why? It’s simple: the AI can validate its mapping against the schema. Tediware uses an iterative loop to drive validation errors to zero. You can try this for yourself in the mapping demo.
Why automation?
Implementation guides are long and complicated and building them by hand is deadly boring. In the case of my company, there’s no time to do it by hand anyway. We run lean and efficient. Our goal is to increase the number of trading partners we work with and the volume of transactions we process without increasing headcount in parallel. That means automating repetitive tasks as much as possible.
How good is the process?
It’s very good, but it’s not perfect. I still do a manual review of the end result to make sure that it’s high quality. A couple of days ago, I imported the full set of retail documents for Petco: 810, 812, 846, 850, 856 and 860. I spent about 1.5 hours reviewing and refining them afterwards, which is not nothing: but for six guides containing 122 segments, 29 loops, 382 elements and 405 allowed codes, plus conditions, syntax notes and so on, I think it’s pretty amazing.
1. What Is “Spec Ingestion”, Exactly?
X12 defines a base standard: transaction sets (e.g. 210, 856, 810), segments (e.g. REF, N1, HL), elements with element codes, loops and syntax notes. Every trading partner publishes an implementation guide on top of that standard for each transaction set that they use.
The guide is a subset with overrides:
- A subset of the standard’s segments and elements are used.
- Status is overridden: an X12-optional segment may be partner-required.
- Code lists are narrowed: REF-01 in the standard has dozens of qualifiers; the partner allows three.
- Validation is layered on: “if REF-01 is BM, REF-02 must be present.”
- Structural variations appear: the same segment position holds several variations distinguished by a qualifier.
- Element types are sometimes overridden too: an alphanumeric element is redefined as an ID and custom codes are defined for it.
A correct ingestion process produces a relational representation of all those things that is still tied to the X12 standard. It must be suitable for both inbound parsing/validation and outbound generation.
Turning a 38-page Walmart 210 spec into something that lives in a database is a structured knowledge extraction problem against a complex target. This is a different problem from “convert this PDF to JSON” — it needs a solution designed to match the conceptual structure of the data model we’re targeting.
It’s also a problem that cannot be reliably solved with a single prompt. Try it yourself: drop an implementation guide into two instances of Claude or ChatGPT and ask for a JSON representation of it. Not only will the end results contain numerous errors and omissions, but the two outputs will be substantially different.
2. Why X12 Is Harder Than It Looks
Before we discuss architecture, let’s calibrate.
Standard vs. implementation. The right model does not re-encode the standard for every partner. It references the standard and stores only the partner’s deltas. This is a data-modeling decision, but it determines the agent’s job, which is to extract differences, not everything.
Hierarchical levels. Transaction sets like 856 use hierarchical level (HL) segments to build dynamic trees, such as Shipment -> Order -> Tare -> Item. The same segment code can appear at multiple levels with completely different meanings. REF at the Shipment level lists carrier/BOL references; REF at the Order level lists invoice/vendor references.
Alternates. A single segment position frequently hosts multiple variations differentiated by a qualifier element. REF*BM (Bill of Lading) and REF*CN (Carrier Reference) occupy the same position in the spec but have different code lists, requirement levels, and notes. Loops can have alternates too, sometimes with different segment lists per alternate: one variation of the N1 loop might include ITD while another does not.
Conditional rules. These are derived from X12’s syntax notes plus partner-specific overlays. These enforce rules like, “X is required when Y = Z”, “X is required when Y is present”, “X must not be included when Y is present”, and so on. Some of these can be modeled as alternates and some cannot. Confusing the two categories produces a schema that is either wrong or unbuildable.
Format variability. Implementation guides arrive as PDF, Word, HTML, partner portal exports, occasionally Excel. Tables get re-flowed across page breaks. Footnotes link to qualifier codes. Some sections are narrative.
Guides contain errors. I’ve encountered errors, inconsistencies and contradictions in implementation guides, even those published by Fortune 500 companies. Some tolerance must be built in. Sometimes, the intent of the implementation guide must be inferred, i.e. we must follow the spirit of the guide, not its letter.
X12 licensing restrictions. X12 prohibits the ingestion of X12 data into AI models. If you’re a licensed X12 partner like Tediware, the process you use needs to comply with the license. In Tediware’s process, what gets read by the models is the trading partner’s guide, not X12’s data. Tools like the command-line extraction tool described in Section 5 tell the model when, for example, they’re attempting to write a code that isn’t in X12’s list of allowed codes for a given element. The process does not give the model the full list of X12 codes.
3. Infrastructure
A successful pipeline requires two pieces of infrastructure that exist before any agent runs. Much of the difficulty in this work is in these two artifacts. Getting them right makes the pipeline (mostly) mechanical and provides leverage. Getting them wrong creates problems that no amount of prompt engineering can solve.
3.1 The X12 Reference Schema
You need a clean, queryable representation of the X12 standard at the release versions you support (at minimum 4010 and 5010: Tediware supports all releases). The schema needs:
- Transaction sets and their tables (heading, detail, summary).
- Segment definitions, with elements, positions, types, requirement codes.
- Element definitions with their full code lists and descriptions.
- Loop definitions with first-segment derived requirement.
- Syntax notes (the canonical X12 conditions: P, R, C, E, L).
- Composite element structure.
release = X12::Release.find_by(code: "005010")
X12::TransactionSet.find_by(code: "856", x12_release: release)
.x12_loop_definitions
.includes(x12_segment_uses: { x12_segment: :x12_elements })
This is licensed material from X12. You either license the data directly or derive it from a licensed source. Without this, the model will confabulate qualifier codes that look plausible but do not exist. You can get a sense of the data model that Tediware uses by accessing the X12 Reference.
3.2 The Implementation Data Model
This is the target of the entire process and it’s worth significant investment to get right. Every aspect of the pipeline downstream depends on whether this model can represent what appears in real-world implementation guides.
As I was building the data model, I also built UI for it: a static HTML “show” view, and UI views for editing it as well. Every change to the data model necessitated changes to the views. This served as an additional verification for what I was building. If I could see it and edit it, and it made sense, I was confident I was on the right track.
These are the core tables for the implementation data model in Tediware:
implementations
-> implementation_loop_uses (subset of X12 loops, with overrides)
-> implementation_segment_uses (subset of X12 segments, with overrides)
-> implementation_element_uses
-> implementation_component_uses (for composites)
-> implementation_hl_levels (for HL-based transaction sets)
-> implementation_conditions (polymorphic, on loops/segments/elements/components)
Every *_use references its X12 base record. Inheritance flows from the standard; only deltas are stored. The data model is complex: certainly among the most complex data models I’ve created in my career. At one point I generated entity-relationship diagrams for the model, printed them out and put them on my office wall so I could study them (or just reassure myself I wasn’t on a wild goose chase).

Here are the key design decisions.
Discriminant-based alternates. When a segment position has multiple variations, each variation is its own SegmentUse row, distinguished by two fields:
discriminant_element_position # which element identifies the alternate (1-based)
discriminant_value # the X12 code value (e.g. "BM", "CN")
This constrains the model deliberately: all alternates at a position must use the same discriminant element position.
Alternates have their own enum. Rather than detect the alternate pattern at runtime, both SegmentUse and LoopUse carry an alternate_type enum:
none = 0
segment_level = 1 # multiple segments at same position, different element values
loop_level = 2 # part of a loop alternate, inherits from parent LoopUse
This is a self-documenting choice that pays off in subsequent steps.
HL hierarchies are first-class and orthogonal to alternates. HlLevel is its own entity with a self-referential parent. Segments and loops attach to a level via FK:
implementation_hl_levels: id, level_code, level_name, position, parent_id
implementation_segment_uses.implementation_hl_level_id (nullable)
implementation_loop_uses.implementation_hl_level_id (nullable)
The crucial property: HL levels and discriminant-based alternates are independent. A REF segment at the Shipment level can still have qualifier alternates (BM vs. CN). The alternates scope is bounded by implementation_hl_level_id, so a REF at the Shipment level and a REF at the Order level are not considered alternates of each other; they are independent groups.
Discovering this independence is the kind of insight that retroactively invalidates earlier modeling attempts.
Conditions are polymorphic and independent from X12 syntax notes. Trading partner validation rules live in implementation_conditions with a polymorphic parent. The condition types parallel the X12 standard:
required # at least one of N elements present
paired # if any present, all required
conditional # if trigger present, dependents required
excluded # only one of N may be present
list_conditional # value-dependent logic
Partners may borrow from X12 syntax notes as templates but customize freely. This also lets us model constraints that the alternate model cannot represent (more on this in Section 6).
Status and repetition are overrides. Every *_use has status (required/optional), and repeatable items have min_reps, max_reps. These override the X12 base. A loop that is optional in the standard can be marked required for a specific partner.
The JSON schema is derived from the relational model. The JSON schema is generated from it for runtime validators. This is a tremendously powerful design. I can edit the implementation guide in the aforementioned UI and the JSON schema is regenerated automatically, ready for use in the data processing pipeline.
4. Why the Pipeline Is Phased
A monolithic “extract this implementation” prompt fails for three concrete reasons:
- Token budget. A 200-page spec plus the target schema plus extracted data exceeds practical context windows. Aggressive summarization causes data loss in unpredictable places.
- Attention dilution. Asking a model to simultaneously identify HL levels, detect alternates, narrow code lists, and extract conditions causes confusion between concerns.
- No verification surface. A single 80-thousand-token response is unauditable. There is no intermediate artifact to diff, no per-stage validator to run, and no place to inject a human correction.
The solution is to decompose along the conceptual structure of the target model. Each phase produces one kind of artifact, in a fresh agent context, with a prompt written just for that phase.
The orchestrator is deliberately dumb. It validates inputs, spawns one agent per phase, extracts two or three structured values from each response (an HL boolean, an implementation GUID), and routes accordingly. The intelligence lives in the per-phase instruction documents.
Phase 0 Setup folder structure, hints file
Phase 1 Structure PDF/Word/HTML -> canonical markdown
Phase 2 HL detect is this HL-based? extract level tree
Phase 3 Alt detect identify alternate positions (no extraction)
Phase 4A Extract basic loops/segments/elements/codes -> JSONL
Phase 4B Extract HL levels and segment mappings -> JSONL (gated)
Phase 4C Extract alternates -> JSONL
Phase 4D Extract conditions -> JSONL
Phase 4E Extract notes -> JSONL
Phase 5 Import JSONL -> relational, returns implementation GUID
Phase 6 Review re-read spec, audit imported data
Phase 7 Deviations optional, analyze X12 standard violations
Each phase is a separate Task invocation with a fresh context. Each writes its output to disk before the next phase reads it. The materialized intermediates are the system’s audit trail.
5. Why JSONL
The intermediate format between Phase 4 and Phase 5 is JSON Lines: one JSON object per line, no surrounding array, no commas between records.
{"type":"loop","loop_id":"0100","name":"Name","position":1,"usage":"optional"}
{"type":"segment","segment_code":"N1","loop_id":"0100","position":1,"usage":"required"}
{"type":"element","segment_code":"N1","position":1,"usage":"required","allowed_codes":{"ST":"Ship To","BT":"Bill To"}}
These records are simplified for illustration. Real records carry additional fields (names, table areas, repetition limits, notes, X12 requirement codes, and so on) and live in separate per-type files rather than in a single mixed stream.
The JSONL format is perfect for this use-case:
Append-only and streamable. Phase 4 writes records as it produces them. A partial run leaves a partial file that is still valid (every prefix is valid JSONL). A standard JSON array would be truncated and unparseable.
Per-record validation. Each line is independent. A single bad record fails one line, not the file. The validator can report “line 47: missing required field position” without losing the rest.
Diff-friendly. Re-running Phase 4C and comparing alternate sets is a line-by-line diff. A single JSON document with nested arrays produces unreadable diffs.
Cheap to filter. grep '"type":"alternate"' file.jsonl is a useful command. jq over JSONL works one record at a time without loading the whole file.
Built up over multiple phases. Phase 4A through 4E each produce their own JSONL stream. Phase 5 reads them in order and assembles the database state. No single phase needs to hold the full implementation in memory.
I wrote a small CLI tool that is used to write data to the JSONL files. Using it looks like this:
# Write a validated record
./tools/x12-extract/bin/x12-extract \
--type segment \
--output ai/implementations/partner/structured_data/856/ \
--data '{"segment_code":"REF","loop_id":"0200","position":3,"status":"optional"}'
This tool validates at write time. This gives the agent immediate feedback on its actions. Contrast this with a strategy of writing everything, then trying to import it all at once: now you’re dealing with errors in a process that is significantly disconnected from where they came from.
The CLI tool also supports validating entire directories of JSONL files:
# Validate a directory of JSONL files
./tools/x12-extract/bin/x12-extract --validate ai/implementations/partner/structured_data/856/
This creates yet another opportunity for checkpoints in the prompt: “Once extraction is complete, validate all extracted data”, etc. You should build the validator CLI before you build the extraction steps!
6. The Stages in Detail
Each phase runs in its own agent context. The orchestrator passes the partner name and transaction set code as arguments; everything else comes from disk.
6.1 Phase 0: Setup
Creates the working directory structure:
ai/implementations/{partner}/
spec/ # original source documents
working_notes/{transaction_set}/
alternate_hints.md # optional, human-seeded
structured_data/{transaction_set}/
loops.jsonl
segments.jsonl
elements.jsonl
codes.jsonl
hl-levels.jsonl
hl-segment-mappings.jsonl
segment-alternates.jsonl
loop-alternates.jsonl
conditions.jsonl
notes.jsonl
The optional alternate_hints.md is worth highlighting. A human reviewer who has skimmed the spec can write down patterns they expect to see (“REF in loop 0200 has BM and CN alternates”; “N1 loop has ST, BT, RI variations”). Phase 3 and Phase 4C read this file and cross-check their own detection against it.
This is the main point of human-in-the-loop steering in the pipeline. The agent is free to find things the human did not list, but it is required to explain any item from the hints file it did not find.
6.2 Phase 1: Spec to Structured Text
Input: the raw spec (PDF, Word, HTML).
Output: a canonical markdown document representing loops, segments, elements, element codes, conditions, and notes in a uniform format.
Why this is its own phase:
- Agents work better from structured text than PDFs.
- A single structured source document can be easily viewed, edited, and audited after the fact if there are issues in the pipeline.
Common failure modes:
- Code lists split across pages get truncated. Mitigation: an explicit “verify every code list has a closing row before moving to the next segment” instruction.
- Composite elements get flattened. Mitigation: a separate notation in markdown for composite vs. simple elements.
- Qualifier descriptions get paraphrased. Mitigation: copy descriptions verbatim from the source.
The markdown is the single point of truth for every subsequent phase. Phases 2 through 4 do not re-read the original spec.
6.3 Phase 2: HL Detection
Input: the markdown from Phase 1.
Output: a binary IS_HL_BASED and, if true, a level tree.
Why a binary phase: the answer determines whether Phase 4B runs and shapes how Phases 4A and 4C interpret segment ownership. Getting this wrong messes up the subsequent phases.
The orchestrator extracts the value from the agent’s structured response and propagates it. The classic 856 hierarchy:
Shipment (S) position 0 parent: nil
Order (O) position 1 parent: S
Tare (T) position 2 parent: O
Item (I) position 3 parent: T
Variations like SOPI (substituting Pack for Tare) or SOI (collapsing Tare entirely) are common. Phase 2 detects which variation this spec uses.
6.4 Phase 3: Alternate Detection
Pure detection, no extraction. The output is a list of positions that host alternates, classified as segment-level or loop-level. This information is cross-referenced against alternate_hints.md.
Why detection is separate from extraction: alternates are, to be frank, the flakiest part of the process. They depend on judgment instead of a straight “translation”. A dedicated detection pass with hints in the loop catches patterns that slip past a combined extractor. By the time Phase 4C runs, it has a checklist of what it should find.
Output looks roughly like:
Segment-level alternates:
REF in loop 0200 (discriminant: element 1)
BM - Bill of Lading
CN - Carrier Reference Number
DP - Department Number
Loop-level alternates:
Loop 0300 (N1) (discriminant: first segment element 1)
ST - Ship To (segments: N1, N2, N3, N4)
BT - Bill To (segments: N1, N2, N3, N4)
RI - Remit To (segments: N1, N2, N3, N4)
CN - Consignee (segments: N1, N2, N3, N4, ITD)
The fourth variant in the last group (different segment list) is the kind of thing Claude is not going to get right if you just dump a PDF into a chatbox.
6.5 Phase 4: JSONL Extraction
This stage uses five focused extractors, each of which writes to its own JSONL file. Each is independently validatable via the extraction CLI.
4A: Basic structure. Loops, segments, elements, codes. This is the bulk of the volume.
4B: HL levels and segment mappings. Skipped when IS_HL_BASED=NO. Extracts the level tree and the assignment of each segment to a level. This is where REF-at-Shipment and REF-at-Order get differentiated.
4C: Alternates. Cross-checks against the hints file. Produces segment-alternates.jsonl and loop-alternates.jsonl. Each record carries the discriminant element position, the discriminant value, the alternate sequence, and alternate_repeats to distinguish “appears once” from “appears many times with different qualifiers.”
4D: Conditions. Extracts validation rules, including patterns that cannot be modeled as alternates. Required fields, exclusions, dependencies, etc., are all extracted in this step.
4E: Notes. Implementation-specific guidance, qualifier explanations, anything narrative that should travel with the data.
After 4E, the structured_data directory is a complete, validated, machine-readable representation of the implementation.
6.6 Phase 5: Import
This phase reads the JSONL files in dependency order, opens a single transaction, creates rows and returns the implementation GUID when it’s done. Phase 5 is, more-or-less, mechanical. If import is hard, the JSONL is wrong, not the importer.
Typical order:
1. implementations (the row itself)
2. implementation_hl_levels (parent-before-child traversal)
3. implementation_loop_uses (independent of segments)
4. implementation_segment_uses (FK to loop_uses, hl_levels)
5. implementation_element_uses
6. implementation_component_uses
7. implementation_conditions (polymorphic, last)
The implementation GUID is captured by the orchestrator and passed to Phase 6.
6.7 Phase 6: Review and Validate
This uses a fresh-context agent that reads the Phase 1 markdown, queries the imported implementation through the data model, and produces a review document that flags:
- Loops or segments present in the spec but missing from the import.
- HL level assignments that look wrong.
- Alternates with invalid discriminants (value not in allowed_codes).
- Narrowed code lists that dropped a required code.
- Condition coverage gaps.
- X12 standard deviations: places where the partner’s spec violates the base standard.
The deviation log matters. Real partner specs frequently violate X12. Marking REF-02 as optional when the standard requires it is not a bug in the importer; it is a fact about the partner. These get flagged in Phase 6 and (optionally) analyzed in Phase 7.
The review document is the artifact a human reads to sign off on the implementation.
6.8 Phase 7: Deviation Analysis
Optional. Runs only if the imported implementation guide shows deviations from the X12 standard.
The default behavior of the pipeline is to faithfully transcribe what the partner’s implementation guide says. If the guide marks an element as Mandatory, it gets imported as Mandatory, even when that conflicts with X12 syntax rules. The spec is authoritative; the importer is not in the business of correcting the partner.
But some deviations are not the partner being opinionated, they are the partner being self-contradictory. An exclusion rule between two elements that are both marked Mandatory cannot be satisfied. A conditional rule referencing an element that is always present is redundant. These cases produce impractical validation behavior, and a literal transcription propagates the contradiction into the schema.
In Tediware, an implementation that has deviations from the X12 standard surfaces them as warnings. Phase 7 reads these warnings, locates each one in the structured markdown, and produces a per-deviation analysis: what the spec says, what X12 expects, where they conflict, what happens in practice if it’s left alone, and a recommended action with reasoning. The output is decision-ready.
Crucially, Phase 7 does not change anything on its own. It presents the analysis and waits. The human decides which (if any) recommendations to apply; only then does the agent modify the relevant JSONL files and reimport.
7. Overall Learnings
The things that took months and do not appear in any single phase.
Decomposition is a model-design tool. Each phase boundary corresponds to a type of cognitive work the model should do separately. The HL detection phase exists because confusing HL-membership with alternate-membership is an error that happens when both are in scope simultaneously.
Human-readable intermediates are key. Markdown between Phase 1 and Phase 4, JSONL between Phase 4 and Phase 5 and review documents from Phase 6. Pipelines without intermediates are pipelines without audit trails. Getting this right requires iteration. Iteration without documentation is flying blind.
The data model is the foundation. Most of my time was spent refining the data model. I made numerous significant changes over weeks of testing and experimentation. Each change required a refactor of everything that touched the model. Spend disproportionate time here. Create a UI for implementations and hand-build at least two of them before you build an extraction pipeline.
Hints provide an opportunity for human-introduced subtleties. The alternate_hints.md file is a quiet but important pattern. A human reviewer who has skimmed a spec can list the alternates they expect, and the agent uses that list as a checklist. This is human-in-the-loop steering at a high-leverage point: hints are cheap to write, the agent is free to find more, and any item from the hints that the agent did not find is automatically a question worth answering.
Verification belongs in a separate context. The same model that produced an extraction cannot reliably audit its own output in the same context. A fresh agent reading the markdown alongside the database catches errors that the extraction agent could not.
The reference data is essential. The biggest single failure mode of any LLM-based approach to this is made-up data: qualifier codes, incorrect segment positions, made-up loops. Without a queryable X12 schema to anchor against, models produce plausible-seeming, incorrect data. The reference schema is the guardrail that keeps the process on track.
Build the validator first. The extraction CLI with a --validate flag exists before any extractor is written. The validator’s schema is the contract that extractors target and import reads. Without this, errors found at import time have no clear owner.
8. Conclusion
If you’re going to go down this road, I hope I’ve provided a useful map that gets you started in the right direction. If you’re interested in learning more about my process or about Tediware, I’d love to hear from you. Drop me a line at adrian@tediware.com or book a meeting with me.